I’m using memcache with w3c total cache plugin to cache pages on my wordpress site on Ubuntu Linux. The way it works is whenever someone hits a page, that page gets cached. But the first user has to see higher latency. This is not such a huge problem if you have lots of traffic. Only a small fraction of users will see that higher latency. But if you are obsessed with site performance, you can reduce latency for even first time users with cache preload.
W3 total cache plugin and page cache preload
Cache preload can be done using w3 total cache plugin’s feature to preload cache using wordpress cron. You can go to page cache -> cache preload and set click on automatically prime the page cache as shown below:
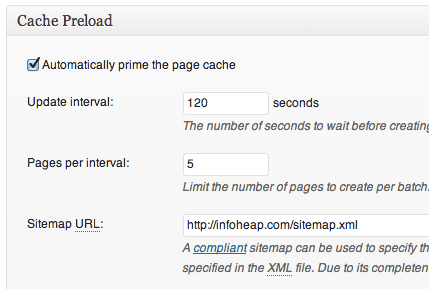 Few points to note:
Few points to note:
- the cron will iterate over sitemap and will preload the defined number of urls (one batch at a time) in order of sitemap priority. It may happen that a url which has expired cache object may get its turn later than other non expired url cache objects.
- The cache does not get refilled if the url is about to expire. So there is always a window when url is not cached.
- You may want to increase the maximum lifetime of cache object for better performance.
Using Linux cron to pre-load cache
This approach gives you better control over cache preload. This can work well if the number of articles on the site is a manageable set. Here are the steps:
- First keep a high value of cache expiration value. I’m using 10 hours. That way cache preloading process won’t have to run too frequently.
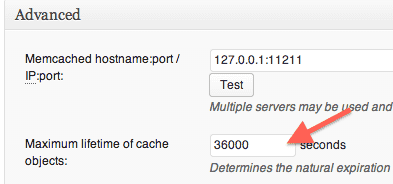
- Write a bash shell script to pick all urls from the sitemap file and fetch them one by one. Here is sample code which you can use as starting point:
#!/bin/bash set -e URLS=`cat /path/to/sitemap.xml | grep "<loc>" | awk -F"<loc>" '{print $2} ' | awk -F"</loc>" '{print $1}' | egrep "http"` count=`echo $URLS | wc -w` i=0 for URL in $URLS do i=$((i + 1)) echo "Fetching $URL ($i/$count)" wget -q -O - $URL > /dev/null sleep 1 done - You may also want to include urls like http://HOST/page/2/, http://HOST/tag/sometag/page/2/, etc. in the script as these are usually not included in sitemap.
- Also add memcached restart command in the script so that when we fetch urls, they get reloaded and cached again instead of just returning old cache values.
sudo service memcached restart
In case the number of article are large on your site, you may want purge one url at a time instead of restarting the whole memcache server. - Now schedule the bash shell script as Linux cron at some interval which is less than the cache expiration time (10 hours in our case). It can be every 6 hours.
Note that in this approach cache get reloaded fully at specific interval. While cache is getting loaded, the url latency will be high for users accessing the site at that time. So this approach works best if the number of articles to manage is not huge. Tentatively for a site with 1000 or so articles, cache loading can happen in 10 min or so for AWS small EC2 instance.
Impact on SEO
Faster loading sites are always good for users and hence site performance is linked to SEO as well. Google also shows crawl stats (time spent in downloading a page) in webmaster tools under Health section. Here is how it looks:
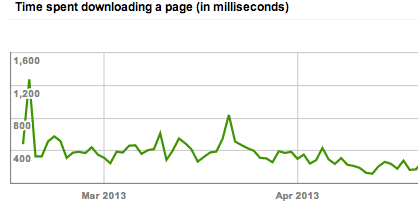 I think an average download time less than 0.5 seconds should be considered good. But you should try to have download time as low as possible. using cache preload for all pages can lead to pretty good improvement in site performance and the average download time.
I think an average download time less than 0.5 seconds should be considered good. But you should try to have download time as low as possible. using cache preload for all pages can lead to pretty good improvement in site performance and the average download time.



